Keras介绍
Keras设计原则
- 用户友好
- 模块性:网络层、损失函数、优化器、初始化策略、激活函数、正则化方法都是独立的模块,你可以使用它们来构建自己的模型。
- 易扩展性:添加新模块超级容易,只需要仿照现有的模块编写新的类或函数即可。
- 与Python协作
Keras快速上手
- Keras核心数据结构是模型,模型是一种组织网络层的方式,主要模型是Sequential模型,Sequential是一系列网络层按顺序构成的栈
- 在Sequential中,通过.add()将网络层堆叠起来,就构成一个模型
- 完成模型搭建后,使用.compile()来编译模型
- 编译模型时,必须指明损失函数和优化器,也可以自己定制损失函数。Keras中,用户可以根据自己的需要定制自己的模型、网络层、甚至修改源代码
|
|
- 完成编译后,调用.fit()进行模型训练。也可以手动调用一个个batch进行训练
- 随后使用一行代码对模型进行评估
- 使用.predict()对新数据进行预测
|
|
Keras中的一些概念
Keras后端
Keras底层库使用Theano或TensorFlow,Theano和TensorFlow都是“符号式”的库。符号这一的计算首先定义各种变量,然后建立一个“计算图”,计算图规定了各种变量之间的计算关系,建立好的计算图需要编译以确定其内部细节,此时的计算图还是一个“空壳子”,没有任何实际数据,当把需要运算的输入放进去后,才能在整个模型中形成数据流,从而形成输出值。
tensor(张量)
张量可以看做向量、矩阵的自然推广。张量的阶数也称为维度或轴。
- 规模最小的张量是0阶张量,及标量,就是一个数
- 一些数有序排列,就形成1阶张量,就是一个向量
- 2阶张量,就是一个矩阵
- 3阶张量,就是一个立方体
Sequential模型
- Keras中,Model接收一个或一些张量作为输入,然后输出一个或一些张量,最特殊的模型是Sequential序贯模型。
batch
- 深度学习的优化算法就是应用梯度下降,每次参数更新有两种方式
- 遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度。成为batch gradient descent,批梯度下降。
- 每看一个数据就算一下损失函数,然后求梯度更新参数,称为随机梯度下降(stochastic gradient descent,SGD)。
- 一种折中方法,mini-batch gradient descent,小批梯度下降,这种方法把数据分为若干批,按批更新参数,这样,一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面批的样本数与整个数据集相比小了很多,计算量也不是很大。
- Keras的batch_size就是指一次训练的数据大小
epochs
epochs指的就是训练过程中数据将被重复使用多少次。
Keras使用
Sequential序贯模型
- 序贯模型是多个网络层的线性堆叠
- 可以向序贯模型传递一个layer的list,也可以调用.add()方法将layer一个个加入模型。
输入数据shape
- Sequential第一层需要接受一个输入数据shape的参数,有以下机种方式制定第一层shape
- 传递tuple类型的数据input_shape给第一层
- 如Dense层,支持input_dim指定输入数据shape,一些3D层支持input_dim和input_length指定输入shape
编译
- 在训练模型之前,我们需要通过compile来对学习过程进行配置,compile接受三个参数:
- 优化器optimizer:可指定已预定义的优化器名,如
rmsprop、adagrad,或一个Optimizer类的对象 - 损失函数loss:模型试图最小化的目标函数,可制定预定义的损失函数名,如
categorical_crossentropy、mse,也可以为一个损失函数 - 指标列表metrics:对分类问题一般设置为
metrics=['accuracy']。指标可以是一个预定义指标的名字,也可以是用户定制的函数。指标函数应返回单个张量或一个完成metric_name->metric_value映射的字典- 性能评估模块提供一些列用于模型性能评估的函数
- 性能评估函数类似目标函数,只不过性能评估结果不会用于训练
- 性能评估函数输入参数:
- y_true:真实标签,theano/tensorflow张量
- y_pred:预测值, 与y_true形式相同的theano/tensorflow张量
- 性能评估函数返回值:单个用以代表输出各个数据点上均值的值
- 优化器optimizer:可指定已预定义的优化器名,如
训练
- Keras以Numpy数组作为输入数据和标签的数据类型,训练模型一般使用.fit()函数。
Functional模型
- Keras函数式模型接口,是用户定义多出输出模型、非循环有向模型或具有共享层的模型等复杂模型的途径。
- 函数式模型是最广泛的一类模型,序贯模型(Sequential)是函数式模型的特殊情况
全连接网络
多输入和多输出模型
- 使用如下模型进行新闻转发和点赞次数预测。主要输入问新闻本身,额外输入是新闻发布日期等,主损失函数评估基于新闻和额外信息的预测情况,辅助损失函数评估基于新闻本身做出的预测。
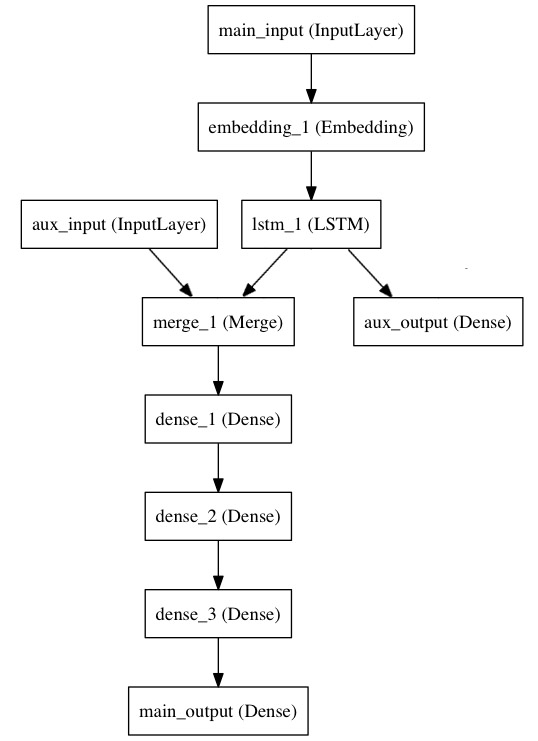
代码如下:
|
|